

How Do You Delete a User From a Model You Already Fine-Tuned?
GDPR and CCPA deletion rights on AI training data: what the law requires and how to comply, explained for teams actually building with user data.

TL;DR
Fine-tuning a model on user-generated content, support tickets, chat logs, or any text containing names, emails, or identifiable patterns comes with a distinct liability under the GDPR and the CCPA. When your user asks you to delete their data and you drop their rows, the model you fine-tuned on those rows still carries them. Deleting a record from a database and removing its influence from a set of weights are different operations, and only one of them is easy. This piece explains why the model holds the data after the row is gone, what each law actually requires of you, why honoring it breaks the training pipeline, and how to build so that a deletion request is something you can answer. It covers the privacy techniques that get you there and the exact pipeline and contract choices that make them work. If you have fine-tuned any model on data your users generated and you have not thought about any of this, this piece is for you.
Legal Layer angle
In this piece, I will cover how to tell which law applies to you and what each one demands, why a deletion request can reach the trained model and not only your data store, the engineering techniques that change your legal exposure, and the provenance, training, and vendor-contract choices that let you actually comply.

When a user emails and asks you to delete their account and everything tied to it, and if you fine-tuned your support model on a year of conversations, theirs among them; things are not as simple as dropping their rows, scrubbing the backups on the next cycle, and closing the ticket. You can do all of that and your database will forget them but the model you fine-tuned will not. If that user, or a regulator acting on their complaint, asks whether their data still lives in your system, the honest answer is that it lives in the weights, in a form you cannot point to, isolate, or fully account for. That gap between the deletion you performed and the deletion the law has in mind is the part of training on user data that almost nobody designs for at the start, and it is where the exposure sits.
Deleting the row is not deleting the data
Let’s start with why the model still has them, because the legal argument rests on this and it is worth understanding rather than taking on faith. When you fine-tune, the optimizer nudges the weights a little for every training example, and those nudges accumulate and overlap across billions of parameters. There is no row in the model that says “this came from user 4471.” The influence is spread out and entangled with everyone else’s, which is exactly why you cannot reach in and pull one person out the way you delete a database record.

One note for how people actually fine-tune: With parameter-efficient methods like LoRA, the base model is frozen and the new learning sits in a small separate adapter. That isolates the influence and makes the adapter cheap to drop or rebuild, which helps the deletion story. It is a partial fix rather than a full one, because the adapter still encodes the data and can leak it the same way the weights of a full fine-tune can. So yes, LoRA helps isolate changes but doesn’t magically solve extraction.
The reason regulators care is that the influence can be pulled back out of the model in practice.
Two well-studied attacks make the point.
A membership-inference attack lets someone determine whether a specific person’s data was in the training set, by probing how confidently the model behaves on it.
A training-data extraction attack goes further and reconstructs actual examples the model memorized, which researchers have demonstrated repeatedly on large language models.
Both are central to how regulators now decide whether a trained model still exposes the people in its training data.
The legal conclusion follows from the technical one:
If a person’s data can be inferred from or extracted out of the model, the model is still holding their personal information, so deleting your stored copy while leaving the model untouched does not finish the job.
Let me also state that risk is not binary or uniform. Fine-tuning a small support-bot adapter on chat logs is higher risk than continued pre-training a frontier model on mostly public/web-scale data with some user signals mixed in. Scale, data sensitivity, and model size matter enormously. Extraction attacks are harder on larger, more capable models in some regimes (they generalize better and memorize less verbatim), though membership inference can still work. So read everything below as scaled to your case, hardest for a small fine-tune on sensitive user text and softer as the corpus grows more public and the model less reliant on any one record.
Which law applies to you, and what each one wants
Two regimes matter for most builders, and they do not trigger the same way, so the first practical step is knowing which one has you.
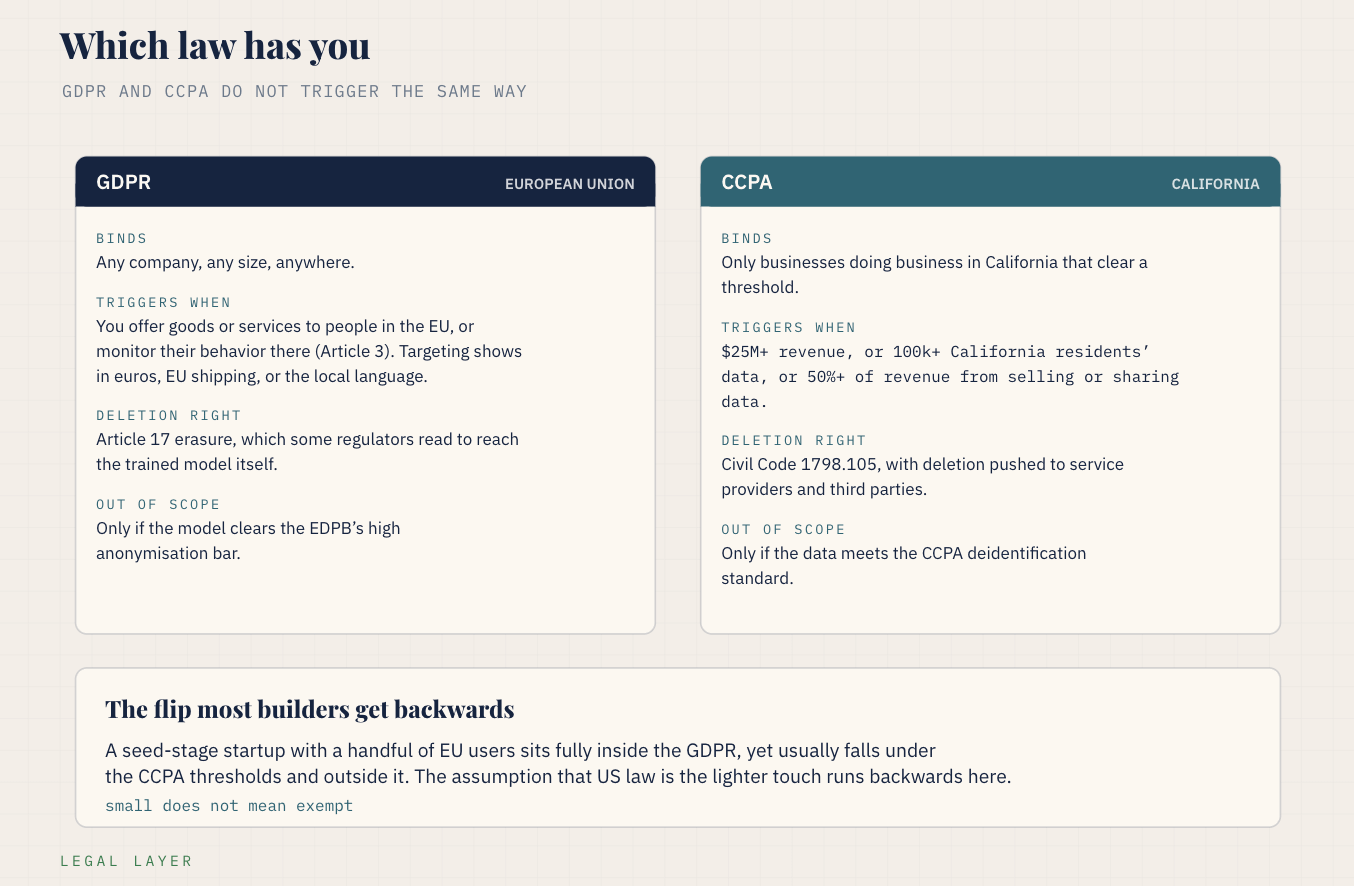
GDPR - General Data Protection Regulation
The GDPR is the European Union’s data protection law, and the trigger is not where your company sits. Under Article 3 it reaches you when you offer goods or services to people in the EU or monitor their behavior there.
A site that merely happens to be reachable from Europe does not count. What pulls you in is evidence that you aimed at the EU market, such as pricing in euros, shipping there, or offering the local language. Clear that, and you are inside it even as a two-person startup in Austin, while a single incidental EU visitor on an otherwise US-focused product may not put you there at all. The analysis is fact-specific, so treat a real EU user base as a yes and an edge case as a question for counsel.
Its deletion right is Article 17, the right to erasure, often called the right to be forgotten. A person can require you to delete their personal data, and the live debate is whether that right reaches only your stored copy or the trained model as well. Regulators are divided. Some treat a model that still exposes personal data as in scope for deletion, while others, including the Hamburg authority in a 2024 discussion paper, argue that a large language model does not store personal data in the relevant sense in the first place. The safer planning assumption is that a model you can extract personal data from is in scope, because that is the reading that leaves you exposed if it prevails.
CCPA - California Consumer Privacy Act
The CCPA is California’s equivalent, as amended by the CPRA, and it triggers differently.
It only binds you if you do business in California and clear a threshold:
more than twenty-five million dollars in annual revenue,
the personal information of a hundred thousand or more California residents, or
at least half your revenue from selling or sharing personal data.
That threshold flips the assumption that US law is the lighter touch, because a seed-stage company can sit under the CCPA entirely while a single qualifying EU user pulls it fully under the GDPR. The CCPA's deletion right is in Civil Code section 1798.105, the right to delete personal information a business collected from a consumer, and California's own legal commentary already reads it the hard way: complying means removing the data from the training set and then making sure the trained model no longer reflects that data, with full retraining named as the reliable path and machine unlearning as the complicated one.
One disclaimer worth stating plainly: no California court or regulator has yet ordered a company to delete data from a model, so this is the direction commentators read the statute.
The shape of the obligation is the same in both: delete on request, and your stored-copy deletion is not the whole of it if the model still carries the person. Two practical features matter to a builder:
First, neither law lets you stop at your own systems. Under the GDPR you have to pass the deletion to your processors, the vendors who handle data on your instructions. Under the CCPA you have to instruct your service providers and contractors, the equivalent role, and notify third parties who received the data, to delete it too. If you fine-tune through a third party, their copy and any model they trained for you are part of your obligation.
Second, both let you refuse in defined cases, the GDPR where you have an overriding legal ground to keep the data and the CCPA through its list of exceptions like completing a transaction or meeting a legal duty, and both let you decline a request you cannot verify came from the actual person. Those are real limits, and they do not cover “deleting it from the model is hard,” which is the one you actually have.
It is worth being honest about the position most companies are actually taking, because it is more defensible than "deleting it is hard" and you will meet it in any serious discussion. The move is to honor deletion in the data store, document a legitimate interest assessment, apply differential privacy where feasible, and argue that this is the reasonable effort the law asks for, with full model surgery as disproportionate. That argument has real footing, and I would not rest a company on it as written. The GDPR's refusal grounds in Article 17 are narrow, and effort or cost is not cleanly one of them. The CCPA does carry disproportionate-effort language, but its application to model deletion is contested and untested, so a reasonable-efforts defense is a live argument you might win, not a settled exemption you can rely on. Treat it as the fallback you raise if a request arrives, and treat the design choices below as what keeps you from needing it.
This is not hypothetical
The proof sits in the United States, in the regulator the CCPA leaves out. Since 2019 the Federal Trade Commission has ordered companies to destroy not only improperly collected data but the models trained on it, a remedy it calls algorithmic disgorgement. It told Cambridge Analytica to destroy the algorithms built from data taken without consent. It made Everalbum, now Paravision, delete the facial-recognition models trained on photos of users who never opted in, and the company filed a report confirming it did. It ordered WW and its Kurbo app to destroy the models built from children’s data collected in breach of COPPA, with a penalty on top. In its 2023 Rite Aid order it went one step further in a way worth your attention: destroy the models derived from the biometric data, and notify any third party holding those data or models to delete them too.
Read those next to this piece and the shape is familiar. The trigger is a training-data problem, the remedy reaches the model and not only the database, and the duty runs downstream to your vendors. One line has to be drawn carefully. The FTC has used this where the data was collected unlawfully, so it is a whole-model remedy for a tainted corpus. It is not yet a per-user “delete me from your model” mechanism, which is the open question the rest of this piece is about. The EU side has its own version of the reach: the EDPB Opinion states that authorities can order erasure of part or all of a dataset, or retraining of the model, where the training data was unlawful. So both regimes already reach the model. What is no longer open is whether a regulator will ever make a company discard a trained model because one has, at least five times.
Why honoring it breaks the pipeline
This is where a compliance question turns into an engineering one. You have a record entangled across the weights and a legal duty to make its influence go away, and your honest options are both unpleasant.
The clean option is to retrain the model from scratch on the data minus that person. It is correct and it provably removes them. Whether it scales depends on what you are retraining: a small parameter-efficient fine-tune can be cheap to re-run, while a full fine-tune retrained on every deletion request, with requests arriving weekly, is a cost few teams can absorb. The expensive case is the common one once the model and the dataset are large.
The other option is machine unlearning, a research area that tries to edit the weights so the model behaves as if it never saw the record, without a full retrain. It splits into exact unlearning, which reorganizes training so you can cheaply recompute the affected part, and approximate unlearning, which estimates and subtracts a record’s influence. Approximate methods are faster and carry no guarantee that the influence is truly gone, and they are least proven on large models, which is exactly where you would want them. There is also no dependable drop-in library you can add to a pipeline and call done, so treating unlearning as a finished compliance control is a mistake you do not want to make in front of a regulator.
The verification problem sits on top. Even after you run an unlearning method, confirming the data is actually unrecoverable is itself unsettled, and a membership-inference test is the closest thing to a check you can run.
Deleting the whole model because one user asked is obviously disproportionate, which is precisely why the targeted version is the open problem, and why the right move is to design so you rarely have to face it.
So here is the call I will defend. Do not rely on unlearning as your deletion mechanism for any model you could not simply rebuild. If your fine-tune is a small adapter you can retrain in an afternoon, unlearning is a convenience you do not need. If it is large enough that a full retrain hurts, approximate unlearning is exactly where it is least proven, so leaning on it means leaning hardest where the ground is softest. The defensible posture is to architect for retraining from the start, sharding the corpus and isolating adapters so a deletion is a partial rebuild, and to treat unlearning as an optimization on top of that, never as the thing you show a regulator. Put plainly: if your answer to "can you prove the data is gone" depends on an approximate unlearning method, you do not yet have an answer.
The solution is making the model not count as personal data
There is a way out of most of this, and it is the same idea in both laws under two names. If the model does not contain personal data, the deletion right has nothing to bite, because there is no personal data in it to erase.
Under the GDPR the concept is anonymisation, and the European Data Protection Board set the bar high.
A model counts as anonymous only when it is very unlikely that anyone could identify the people whose data trained it, and very unlikely that their personal information could be extracted through queries, assessed case by case and documented. A model you can prompt into repeating a training example does not clear it.
Under the CCPA the parallel concept is deidentified data, which falls outside the law when it cannot reasonably be used to identify or be linked to a consumer and you do three things:
take reasonable measures to stop reidentification,
publicly commit to keeping it deidentified, and
contractually bind anyone you share it with to the same.
The two standards are not identical, and they point the same way: clear the bar and the model is out of scope, fail it and the model is personal data you have to be able to delete from.
Clearing either bar is an engineering problem before it is a legal one, which is the bridge to the techniques below. The point of them is to move the model toward not holding recoverable personal data in the first place, which is the position you want to be in when the request arrives.
The techniques that change your legal exposure
Each technique addresses a different part of the problem, and the useful way to hold them is by which legal problem each one solves.

Differential privacy is the strongest of the set, because it bounds how much any single record can influence the model, with a budget you track as an epsilon value. In practice this is DP-SGD: during training you clip each example’s gradient so no one record can move the weights too far, then add calibrated noise, and libraries like Opacus for PyTorch or TensorFlow Privacy implement the mechanism so you are not building it yourself. That bound is what limits memorization, which is what supports an anonymisation or deidentification argument, and it is also formally linked to unlearning, since a record that barely moved the weights is one whose influence is already close to negligible and easier to remove. The cost is real, because a tighter epsilon means more noise and lower accuracy, so you size the budget to the use case rather than flip a switch.
Also newer options scale better to LLMs: DynamoEnhance and DP-ZeRO extensions enable efficient DP fine-tuning on models >7B parameters via DeepSpeed integration and sharding; Google’s VaultGemma (2025) demonstrates strong utility-privacy trade-offs even when training from scratch; and JAX-Privacy offers modular, high-performance primitives for custom mechanisms. User-level DP variants further tighten guarantees when data clusters by individual.
Federated learning keeps the raw data where it was generated, on the user’s device or in the client’s environment, and trains on model updates that get aggregated centrally, with frameworks like Flower or TensorFlow Federated handling the orchestration. It shrinks the pool of personal data you hold and therefore your exposure, though the updates themselves can leak information about the underlying data, so it earns its place when you add differential privacy to those updates rather than running it on its own.
Synthetic data lets you train on generated records that carry the statistical shape of the real data without being any real person’s data, which can break the link to identifiable individuals. The catch is the one most write-ups skip: a generator trained without privacy guarantees can memorize and emit near-copies of real records, so the legal benefit only holds when the generator itself was trained under differential privacy, and you confirm it with a membership-inference test on the output rather than assuming it is clean.
Machine unlearning is the direct attempt to honor a deletion request without a full retrain, by editing the model toward the state it would have reached without the data. The methods live mostly in research rather than in a dependable library, and none give you a guarantee for large models, so treat it as a developing tool, keep a retraining fallback for the cases where you need certainty, and do not represent it to a regulator as proof the data is gone.
Reference-guided methods (e.g., Reference-Guided Unlearning / ReGUn, 2026) leverage held-out reference datasets for principled distillation, helping preserve utility while targeting specific influences more cleanly than pure gradient-based approaches. Complementary techniques like Representation Misdirection Unlearning (RMU) and improved parameter-efficient variants continue to mature, though they remain best paired with provenance, retraining fallbacks, and verification (e.g., membership inference audits) rather than treated as standalone compliance technique.
Building the pipeline so deletion is possible
In the data protection impact assessments I review, the line almost always missing is provenance. A team can tell me what they collected and why. They can almost never tell me which examples actually went into the fine-tune. That one gap is the difference between a deletion you can perform and one you can only promise, because you cannot remove a person from a training set you cannot describe. So the build starts there.
The techniques only help if the system around them was built for this, and that design is the part worth paying for, because it is what separates a defensible position from a hopeful one. The aim is to make “delete this person from the model” a bounded, affordable operation.
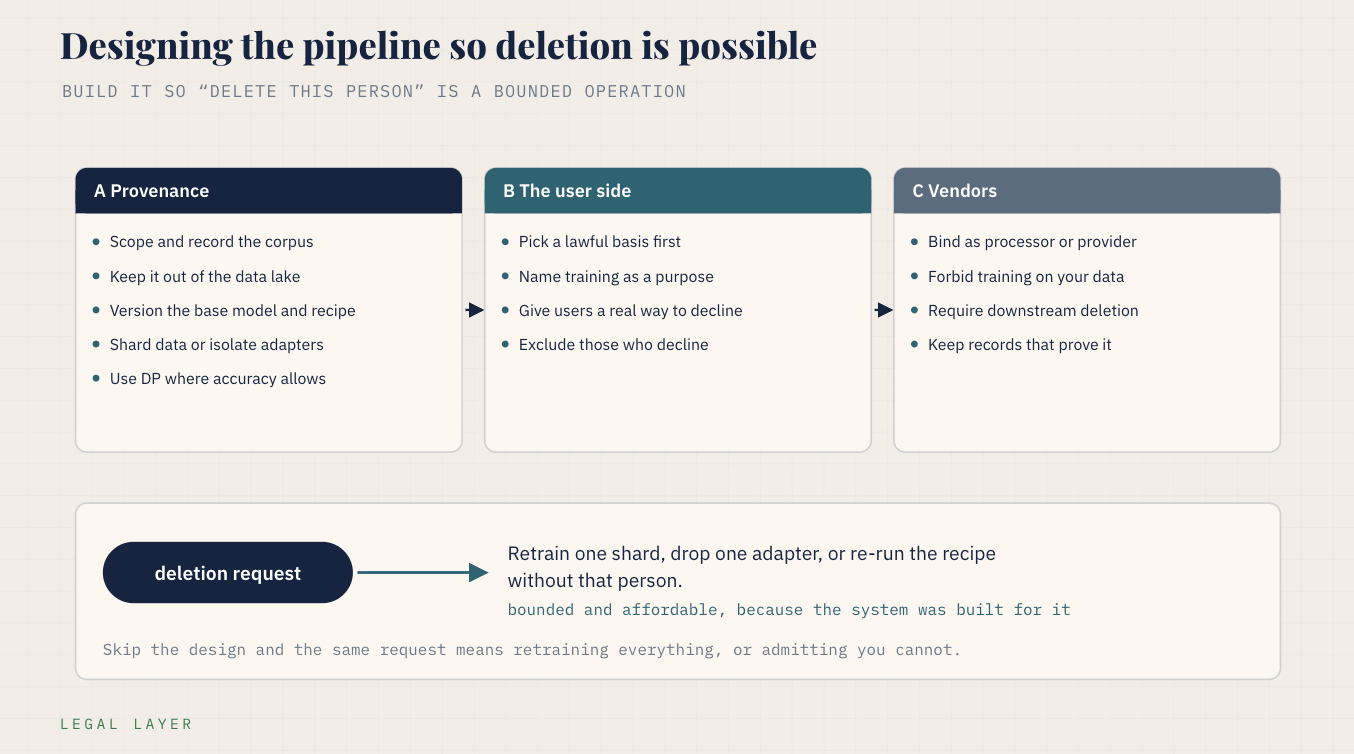
A. Provenance
Start with provenance, because you cannot honor a deletion request against a model if you cannot say whose data was in its training set.
Keep the fine-tuning corpus scoped and recorded, held separately from your general data lake, so that excluding one person is a known change to a known dataset rather than a hunt across everything you have.
Keep the base model and a reproducible fine-tuning recipe under version control, so a clean re-run without a given person is a cost you can plan for instead of a rebuild you avoid.
If you fine-tune with parameter-efficient methods, keep each adapter tied to a known dataset, so dropping or rebuilding one adapter is your cheapest deletion path.
Where the accuracy trade allows, fine-tune under differential privacy with one of the libraries above, both for the memorization bound and for the much stronger deletion story it gives you when someone asks.
Architectures that shard the training data so each shard trains a separable part of the model, the idea behind exact-unlearning schemes, are worth considering when frequent deletion is likely, because they let you retrain only the affected shard.
B. The User Side
Then handle the front door, because what you do at collection decides whether the back door is reachable, and because both laws have requirements there too.
Under the GDPR you need a lawful basis to train on user data at all, which works like an auth check your pipeline has to pass before it touches the data: the law makes you pick, in advance, one of a fixed set of legal reasons, and "we wanted to train on it" is not one of them by itself. For user data you are usually choosing consent, which has to be specific and freely given so a buried terms-of-service line does not count, or legitimate interest, the basis that lets you process without asking each user first as long as you can name a real need, show it is necessary, and show it does not override what the user would reasonably expect, which the European Data Protection Board confirmed can cover training if you run and write down that assessment.
The CCPA does not use consent the same way. It requires you to disclose at collection that you will use the data for training and to keep that use consistent with what you disclosed. Its opt-out rights are narrower than a general veto on processing: a consumer can opt out of the sale or sharing of their data and can limit the use of sensitive personal information, and training on your own users' data is usually neither a sale nor a share, so the disclosure-and-consistency duty does most of the work here, with the sensitive-data limits sitting on top.
The practical move covers both regimes:
tell people at collection that training is a purpose,
give a real way to decline, whether that is withdrawing GDPR consent or exercising the CCPA opt-out and sensitive-data limits, and
exclude the people who decline from the fine-tuning corpus, which is far cheaper than trying to excise them after the model has learned them.
C. The Vendor Relationship
The vendor relationship is the last piece, and the contract is doing legal work there. When you fine-tune on a third-party platform or hand data to a fine-tuning vendor, write the agreement so it pins down the roles, because the roles decide who carries the weight when something goes wrong.
Under the GDPR you are the controller, the one who decides why the data is used, and the vendor is the processor acting on your instructions, so the data processing agreement binds them.
Under the CCPA you want the vendor locked in as a service provider or contractor, which is the status that bars them from using your data for their own purposes, including training their own models on it, and obliges them to pass deletion requests downstream.
Either way the agreement should forbid the vendor from training on your data, commit them to deletion on your instruction, and require them to document the basis on which they process. A warranty that the work is compliant is worth less than the records that prove it, and you want those records to exist before anyone asks for them.
What is settled, contested, and speculative
Settled:
training on personal data needs a lawful basis under the GDPR and accurate notice under the CCPA;
a generic terms-of-service clause is rarely valid consent;
both laws give a deletion right that covers the personal data you hold, including the copies you used to train; and both require you to push deletion to your vendors;
regulators have already ordered whole models destroyed over unlawful training data: the FTC through algorithmic disgorgement, and the EDPB has said EU authorities can order dataset erasure or retraining.
Contested:
whether and when a trained model is itself personal data,
how the deletion right applies to weights rather than records, and
whether approximate machine unlearning satisfies a deletion obligation.
These are live questions without a settled answer, and they shape every team training on personal data.
Speculative:
whether regulators will require unlearning capability or treat retraining as the only acceptable remedy, and
whether the laws will be amended to address models directly rather than through provisions written for databases.
AI systems are lossy compressors of their training distribution, not databases. Laws written for databases create awkward fits. Expect more guidance, enforcement actions, and technical progress on unlearning/privacy-preserving ML. Builders who invest in provenance, strong privacy tech, and transparency will have a real advantage, both legally and in user trust, over those hoping regulators never notice.
If you’re fine-tuning on anything resembling PII, support tickets, or user chats, you should treat it as required reading and do a gap analysis on provenance and lawful basis before your next training run. It’s not impossible to comply, but it is expensive and requires upfront architecture. Ignoring it is playing with regulatory fire, especially in EU-facing products.
Recap
Document the lawful basis or notice before you train, never after.
Keep the fine-tuning corpus scoped, recorded, and separate from your data lake.
Version the base model and the recipe so a clean re-run is affordable.
Apply differential privacy where the accuracy trade allows.
Offer a real way to decline and exclude those users from the corpus.
Lock vendors as processor or service provider, barred from training on your data and bound to downstream deletion.
Further reading
The law and official guidance
European Data Protection Board, Opinion 28/2024 on AI models, the primary source. Read sections 3 and 4 for the obligations on deployers, the anonymisation bar, and the consequences of unlawful training data.
GDPR Article 3 and GDPR Article 17, on territorial scope and the right to erasure, in full text.
California Civil Code section 1798.105 and the CPRA, the right to delete, the duty to pass it to service providers, contractors, and third parties, and the deidentified-data standard that takes a model out of scope.
EU AI Act, Article 10 on data and data governance, the training-data requirements for high-risk systems that sit parallel to the GDPR.
Analysis and enforcement
Norton Rose Fulbright, Data Protection Report: the EDPB Opinion and the Garante fine (January 2025). The clearest read on what it means for deployers, with the fifteen-million-euro OpenAI fine in context.
IAPP: the EDPB on personal data in AI models (February 2026). The most precise walk through the legitimate-interest three-step test, including where the EDPB left the standard deliberately open.
Hunton: EDPB publishes opinion on AI models (December 2024). The fastest practical summary, usable as a checklist alongside the full text.
CMS Law: EDPB Opinion 28/2024 key takeaways. The best short treatment of the unlawful-training-data consequences and how the AI Act and the GDPR interact.
California Lawyers Association, navigating the right to deletion in an era of technologies that do not forget (2026). The single best piece on the deletion-versus-trained-model collision across both the CCPA and the GDPR.
The FTC's model-destruction orders, the precedent where deletion has actually reached the model: the Rite Aid action (2023) and the Everalbum order (2021), with the Debevoise "Model Destruction" explainer for the through-line from Cambridge Analytica forward.
Why the model still holds the data
Shokri et al., membership inference attacks against machine learning models, the proof that you can tell whether a record was in the training set.
Carlini et al., extracting training data from large language models, the proof that records can be reconstructed from a trained model.
Removing it, and where the research stands
Bourtoule et al., Machine Unlearning, the SISA method behind sharded training that makes one-record deletion cheaper.
Nguyen et al., A Survey of Machine Unlearning, for exact versus approximate methods and the link to differential privacy.
The privacy techniques and the tools
Abadi et al., Deep Learning with Differential Privacy, the DP-SGD method, with the Opacus, TensorFlow Privacy, and Google differential privacy implementations.
McMahan et al., the FedAvg paper for federated learning and the Kairouz et al. survey for the whole area, with the Flower, TensorFlow Federated, and PySyft frameworks.
PATE-GAN, the differentially private synthetic-data method and NIST’s plain-language guide to differentially private synthetic data.
I write about legal architecture for AI products at Legal Layer. This piece is informational and does not constitute legal advice; the territorial and lawful-basis questions in particular turn on your specific facts.
Such a great deep-dive. Appreciate the insights